

recap 2022 - part 2 / stable diffusion
2022 – genereren van plaatjes door de computer
Als je een beetje tech-nieuws hebt gevolgd, kan het je niet ontgaan zijn dat er allerhande sprongen in de kunstmatige intelligentie (AI) gebeurd zijn het afgelopen jaar.
Machine learning (ML) bestaat natuurlijk al langer. Maar in 2022 ging de bal voor computer generated images echt rollen. En niet alleen images. GPT-3 en ChatGPT laten zien dat computergegeneerde teksten ook al verbluffend goed kunnen zijn.
DALL-E, dat images kan genereren, geproduceerd door het OpenAI onderzoekslaboratorium bestaat al iets langer dan dit jaar, maar Stable Diffusion 1 (voorbeeld) en alle opeenvolgende versies (1.x en 2.x, door o.a. CompVis, StabilityAI en Runway) zijn allemaal van het afgelopen halfjaar.
“Kleine” datasets
Het indrukwekkende aan stable diffusion (en de aanverwante technieken/datasets) is niet alleen dat ze zo goed plaatjes kunnen genereren, maar ook hoe weinig data er voor nodig is.
De modellen waarmee we op kantoor gespeeld hebben waren allemaal rond de 4 GiB groot tot maximaal het dubbele:
# dutree .
3.6 G ./models/Stable-diffusion/Linaqruf-Anything-V3.0-pruned.ckpt
4.0 G ./models/Stable-diffusion/runwayml-v1-5-pruned-emaonly.ckpt
7.2 G ./models/Stable-diffusion/runwayml-v1-5-pruned.ckpt
4.0 G ./models/Stable-diffusion/sd-v1-4.ckpt
4.9 G ./models/Stable-diffusion/stabilityai-sd-2.0-768-v-ema.ckpt
De Stable Diffusion 1.4 dataset zou op een ouderwetse DVD passen. En omdat de datasets zo klein zijn, is deze techniek voor hobbyisten en kleine spelers binnen handbereik.
Iteratieve verbeteringen
Bij alle modellen geef je een prompt – het gewenste subject – op
waarna de het model in iteratieve stappen het plaatje gaat “verbeteren”.
Bijvoorbeeld dit plaatje van een smiling woman with bright blue eyes, fine, blurry christmas tree background waarbij we opgeven dat blender, cropped, lowres, dark eyes, poorly drawn face, out of frame, poorly drawn hands, blurry, bad art, blurred, text, watermark, disfigured, deformed, closed eyes, heavy lipstick allemaal ongewenst is:

In de interface die we gebruiken – stable-diffusion-webui – zijn aardig wat parameters die je in kan stellen om het resultaat te beïnvloeden. En het lijkt vaak meer geluk dan wijsheid als het een plaatje genereert dat er naar wens uitziet:
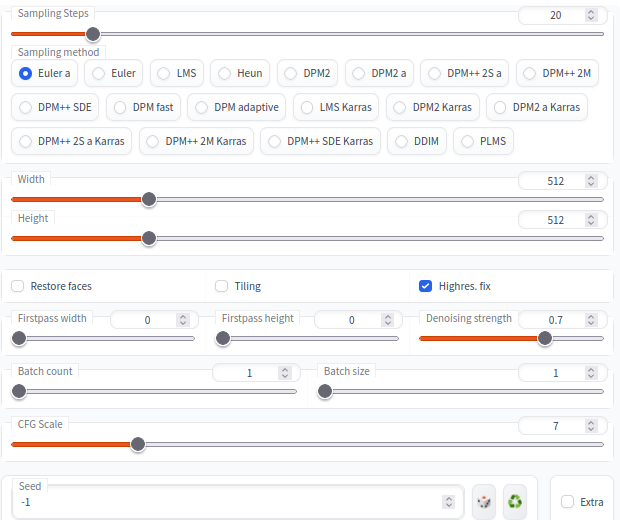
De steps zijn het aantal iteraties dat gedaan wordt. De CFG scale bepaalt in hoeverre de AI af kan wijken van de prompt: hoe hoger, hoe getrouwer de prompt opgevolgd wordt, ten nadele van realisme.
In theorie, althans.
In de praktijk is het hier ook een beetje proberen. Bij het plaatje dat er met CFG scale 7 acceptabel interessant uitzag, krijgen we deze variaties met andere waardes van CFG scale:









Het lijkt hier in de regio 6.5 tot 10 wel okay. Maar, alsnog geeft het geen garanties dat het onderwerp er (volledig) opstaat.









Na CFG scale 10 treden er afwijkingen op waardoor het plaatje al niet meer lekker uitgevuld is: zie de witte balken die verderop zelfs een ovaal rond het plaatje vormen.
Dan hebben we het nog niet over de sampling method, de restore faces en highres. fix opties gehad. En dat zijn dan alleen nog maar de settings voor tekst naar plaatje.
Starten met een plaatje
Je kan ook het plaatje beginnen met een ander (lelijker) plaatje.
Hieronder zie je mijn pogingen om een skyscraper city boven op een berg te genereren. In plaats van met puur de seed te beginnen, wordt begonnen met een ander plaatje als basis. Zo kun je al wat hints geven hoe het resultaat er ongeveer uit moet zien.
We beginnen met dit lelijke gedrocht:

Daarbij de volgende parameters:
- Prompt:
skyscraper city on top of high mountain in rainforest, woods, trees, shiny, fluffy clouds, lots of nature and green and barren rocks - Negative:
bloom, repetition, fractals, ugly, flat, text, rain - Steps:
20, CFG scale:8.5, Denoising strength:0.94
Dit voeren we uit met een aantal verschillende datasets.
Linaqruf Anything v3.0 [hash 2700c435]
Poging één, twee én drie. In één keer leveren alle drie iets wat zowel mooi is als aan de specificaties voldoet:



N.B. Omdat deze dataset met Manga is gevuld, zijn tekenfilm-achtige plaatjes en onderwerpen (getekende meisjes) oververtegenwoordigd in de dataset. Houd dit in het achterhoofd, dit is verderop relevant.
CompVis Stable Diffusion v1.4 [hash 7460a6fa]
Helaas genereerden de andere modellen in de verste verte niet zo
makkelijk dat waar ik aan dacht. Ik heb daar nog wat extra negative
keywords aan toegevoegd – animation, drawing, blender – maar dat
mocht niet veel baten.
Bij een setje van 12 plaatjes zitten er twee of drie hoopgevende tussen:


En dan zie ik het missen van de barren rocks (kale rotsen) even door de vingers.
Veel vaker nog, ziet het eruit als een van deze:


“Thanks SD! Wel een barren rock, maar nu missen m’n skyscrapers." of “Dit was niet de stijl waar ik voor wilde gaan. En geen regenwoud. En geen rotsen."
De plaatjes gemaakt door RunwayML Stable Diffusion 1.5 [hash 81761151] geven min of meer hetzelfde beeld.

Let op: bij image to image generation is de denoising strength van groot belang. Zet je deze te laag, dan blijft je origineel te veel invloed houden. Te hoog, en je invoerplaatje had er net zo goed niet hoeven zijn.
Deze plaatjes met slechts 0.6 denoising strength zien er allemaal meer uit als het origineel. Maar ze zijn ook meteen minder spectaculair:

Om meer veranderingen/verbeteringen te krijgen moeten de steps – het aantal iteraties – dan weer significant omhoog.
Prompt engineering
Als we wat meer gewicht geven aan de barren rocks, komen er soms deugdelijke plaatjes uit.
Prompt: ... lots of nature and green and (((barren rocks)))

Op Reddit en elders zijn hele communities ontstaan die (van) elkaar leren de beste prompts te maken. Bepaalde keywords (“art by van Gogh”, “trendy on artstation”) en negatieve prompts (“fractals, bloom”) kunnen het resultaat flink beïnvloeden. En bij elk model (dataset) zijn die “nuttige” prompts weer anders.
En zoals je zag, maakt de dataset enorm uit: Stable Diffusion v2.0 is beter in mensen, maar het kan allerlei kunststromingen/artiesten niet meer nadoen die v1.4 en v1.5 wel kenden.
Voor de hobbyist is het recept vooralsnog:
- Veel plaatjes genereren, met weinig steps. (Want veel stappen duurt lang.)
- Daarvan de kansrijke pakken. Als je het model, de prompts en en de seed gelijk houdt, genereer je deterministisch hetzelfde plaatje.
- (Als tussenstap kun je nu een kansrijk/beter plaatje terugsturen naar de image to image en die als basis gebruiken om verder te gaan.)
- De kansrijke plaatjes verbeteren door meer steps, kleine denoising- en CFG scale-aanpassingen en kleine prompt-aanpassingen.
- En uiteindelijk upscalen.
Het laatste plaatje hierboven kan ook zeker nog wat postprocessing en upscaling gebruiken.
Hier een voorbeeld van de skyscraper city met StabilityAI Stable Diffusion v2.0 [hash 2c02b20a] na een aantal plaatjes terug te sturen en de prompts aan te passen:

Niet helemaal waar ik op mikte, maar ook leuk…
Leren van gezichten / concepten
Yes! Hiervoor was je gekomen!
Op de OSSO-kerstkaart staan een aantal taferelen afgebeeld met Tux, de Linux mascotte.

Deze hebben we gegenereerd door eerst een zogenaamde embedding te trainen met plaatjes van Tux en daarna prompts te maken waar deze Tux in voorkwam.
Voor zover ik het begrijp voegen embeddings niet data toe aan de dataset, maar vormen ze een manier om een stukje uit de dataset aan te wijzen. Het trainen van een embedding is het zoeken in de dataset naar een plek in de N-dimensionale ruimte waar het onderwerp te vinden is.
Benny Cheung heeft een volledig en informatief artikel geschreven over hoe je embeddings met mensen traint.
Onze eerste tips:
- Train embeddings met 1 of 2 vectoren.
- Neem geen shortcuts. Gebruik genoeg plaatjes. En plaatjes van goede kwaliteit. (En absoluut geen te kleine plaatjes die je geupscaled hebt.)
In ons geval hebben we geprobeerd Tux bij de verschillende modellen te trainen. Helaas gingen we hier redelijk de mist in met te weinig gevarieerde plaatjes. Er zijn nu eenmaal weinig plaatjes te vinden waar Tux anders op staat dan in z’n normale houding.
Maar, na wat trial and error hebben we toch wat kerstige plaatjes kunnen genereren met de Linux mascotte prominent in beeld.
Het middenplaatje uit de kerstkaart toont een interessant verschijnsel waar de training niet volledig weet wat een Tux is, en tegelijkertijd probeert kerktorens en Tuxen te maken, waardoor die samenvloeien.

Het is een mooi plaatje. Maar totaal onrealistisch. Niet alleen door de Tuxtorens maar vooral door de asymetrische spiegelingen in het water.
Natuurlijk ging hier ook het nodige mis:



Deze lijken allemaal een beetje “gesmolten” Tux.


Of een boze Tux. Of een stoffen Tux met misvormde voeten en niet-witte buik.



En met de Anything-trainingsdata – Manga, weet je nog? – leek Tux vooral geassocieerd te worden met dik/mollig. Ik had al eerder genoemd dat in deze dataset getekende meisjes oververtegenwoordigd zijn. Onze Tux embedding was blijkbaar grotendeels blijven hangen in de N-dimensionale meisjes-ruimte en produceerde daarom vaak alsnog meisjes, maar wel met een dikke buik.
Tot slot nog even de minst mislukte versies van de auteur van deze post:


Okay, dat zwaard is wel een beetje jammer.
Overige toepassingen
Al deze ontwikkelingen zijn niet alleen leuk om “kunst” mee te maken door degenen met een minder stabiele penseelhand. De software die de plaatjes maakt is andersom ook heel geschikt in het uitlezen van plaatjes. Bijvoorbeeld voor toepassingen zoals het taggen/sorteren van foto’s (zonder hulp van grote monopolisten).
Sidenote over kunst: het argument dat AI-generated art geen kunst is omdat de computer niks “nieuws” maakt, ga je bij mij niet winnen. Alle goede schilders halen ook hun inspiratie uit hun voorgangers en bouwen daarop voort. Zie ook why AI isn’t copying door Reddit user PhyrexianSpaghetti.
{kind=link}
Ze zijn ook nuttig voor toepassingen die het leven makkelijker maken voor slechtzienden: het uitlezen van inhoud van plaatjes is met CLIP en Deepboru ineens heel erg binnen handbereik voor kleine programmeerprojecten.
Als we het model via CLIP vragen te beschrijven hoe het op dit plaatje is
gekomen, dan krijgen we: a very tall city on top of a hill with a sky background and clouds above it, with a green forest below, by Makoto Shinkai
En een Deepboru lookup geeft: architecture, blue_sky, bridge, building, bush, castle, chimney, city, cityscape, cliff, clock_tower, cloud, cloudy_sky, day, east_asian_architecture, forest, fountain, gate, hill, horizon, house, lake, landscape, mountain, mountainous_horizon, nature, no_humans, ocean, outdoors, path, river, road, ruins, scenery, sky, skyline, skyscraper, sunset, tower, town, tree, water, waterfall
Tot slot
Het zelf installeren van de hardware/software is niet helemaal triviaal. NVIDIA videokaarten zijn aan te raden. Een beetje kennis van Python en Python packaging ook. De software is constant in flux vanwege alle nieuwe ontwikkelingen. En de uitgebreide set dependencies fluctueert ook mee.
Wij blijven hoe dan ook geïnteresseerd en kijken wat de techniek ons in de toekomst nog brengt.
P.S. Bij de meeste plaatjes uit deze blog post kun je de originele prompts en gebruikte datasets (modellen) terugvinden in de PNG metadata:
$ pngmeta <(curl -sSfL \
https://www.osso.nl/assets/images/blog/221221/skyscrapercity-on-mountain-linaqruf.png 2>/dev/null)
pngmeta: PNG metadata for /dev/fd/63:
parameters: skyscraper city on top of high
mountain in rainforest, woods, trees, shiny,
fluffy clouds, lots of nature and green and
barren rocks
Negative prompt: bloom, repetition, fractals,
ugly, flat, text, rain
Steps: 20, Sampler: Euler a, CFG scale: 8.5,
Seed: 2557982197, Size: 640x448,
Model hash: 2700c435,
Denoising strength: 0.94, Mask blur: 4